
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 이탈리아
- IT
- 메시지 큐
- ip
- 여행 #
- 샐러리
- 유럽
- 내심정
- JAVA #언어 #프로그래밍 #코딩 #static #정적함수 #정적변수 #클래스
- 추억
- #DB#SQLD#자격증
- 유럽여행
- 예약
- 경험
- JAVA #언어 #프로그래밍 #IT #개발 #코딩
- 준비
- 여행
- 영국
- 1달살기
- JAVA #객체지향 #프로그래밍 #언어 #IT #기초
- 겨울
- 리눅스
- 배낭여행
- 파이썬
- 서버
- RabbitMQ
- 일정
- 계획
- 인프라
- 실비용
- Today
- Total
YoonWould!!
맵리듀스(Mapreduce) 본문
1. 맵리듀스 개념
맵리듀스 프로그래밍은 맵(Map)과 리듀스(Reduce)라는 두 가지 단계로 데이터를 처리한다.
맵(Map)은 입력 파일을 한 줄씩 읽어서 데이터를 변형(transformation)하며, 리듀스(Reduce)는 맵의 결과 데이터를 집계(aggregation)한다.
특별히 애드혹 분석을 위해 일괄 처리 방식으로 전체 데이터 셋을 분석할 필요가 있는 문제에 적합하다.
<데이터를 한번 쓰면 여러번 익는 응용프로그램에 적합하다.>
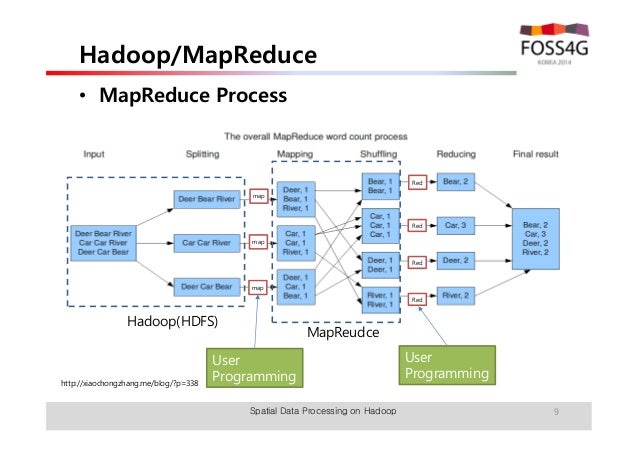
[출처: http://www.slideshare.net/kwnam4u/hadoop-38481079]
2. 맵리듀스 아키텍처
1) 시스템 구성
- 맵리듀스 시스템은 클라이언트, 잡트래커, 태스크트래커로 구성된다.

[출처: http://zetawiki.com/]
- 클라이언트 : 클라이언트는 사용자가 실행한 맵리듀스 프로그램과 하둡에서 제공하는 맵리듀스 API를 의미
- 잡트래커 : 클라이언트가 하둡으로 실행을 요청하는 맵리듀스 프로그램은 잡(job)이라는 하나의 작업 단위로 관리된다. 하둡 클러스터에 등록된 전체 잡의 스케줄링을 관리하고 모니터링 한다.
- 태스크트래커 : 사용자가 설정한 맵리듀스 프로그램을 실행하며, 하둡의 데이터노드에서 실행되는 데몬 잡트래커의 작업을 요청받고, 잡트래커가 요청한 맵과 리듀스 개수만큼 맵 태스크(map task)와 리듀스 태스크(reduce task) 생성
'<IT기술> > 빅데이터' 카테고리의 다른 글
| Mapreduce vs RDBMS (0) | 2018.09.01 |
|---|---|
| 가장 흔해빠진 7가지 하둡 및 스파크 프로젝트 (0) | 2018.09.01 |