
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 준비
- 서버
- 파이썬
- 여행
- 실비용
- #DB#SQLD#자격증
- 배낭여행
- 겨울
- JAVA #객체지향 #프로그래밍 #언어 #IT #기초
- 계획
- 인프라
- 일정
- RabbitMQ
- 유럽여행
- 유럽
- ip
- JAVA #언어 #프로그래밍 #코딩 #static #정적함수 #정적변수 #클래스
- 내심정
- 메시지 큐
- 1달살기
- 예약
- JAVA #언어 #프로그래밍 #IT #개발 #코딩
- 경험
- 이탈리아
- 샐러리
- 여행 #
- 추억
- IT
- 리눅스
- 영국
- Today
- Total
목록<인턴생활> (47)
YoonWould!!
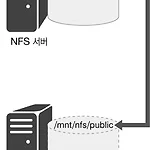 [이론]NFS 서버
[이론]NFS 서버
NFS란 무엇인가요? 공유된 원격 호스트의 파일을 로컬에서 사용할 수 있도록 개발된 파일 시스템을 네트워크 파일 시스템(NFS)이라고 합니다. 전통적인 유닉스 환경에서는 오랫동안 네트워크에서 자료를 공유하는 방법으로 NFS를 사용했습니다. NFS 서버가 파일을 공유하면 NFS 클라이언트가 공유한 디렉터리를 마운트해서 원격 호스트(NFS 서버)의 파일을 사용합니다. ▼ 그림 7-2 네트워크 파일 시스템 NFS는 손쉽게 파일을 공유할 수 있다는 장점이 있지만 보안에 취약하다는 단점이 있습니다. NFS로 공유한 파일에는 일반적인 소유권과 접근 권한이 그대로 적용됩니다. 원격 시스템에서 어떤 사용자가 파일 소유자와 같은 UID로 공유 디렉터리에 접근해서 파일을 마음대로 사용할 수 있습니다. 루트 권한이 부여된 ..
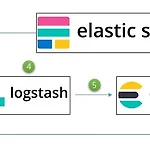 [elasticsearch] apache access log 분석
[elasticsearch] apache access log 분석
외부에서의 접근이 발생하면 apache 웹서버에서 설정한 경로에 access log가 파일로 생성이 되거나 있는 파일에 추가가 된다. 해당 파일에는 한줄당 하나의 엑세스 정보가 남게 된다. fileBeat에서 해당 파일을 트래킹 하고 있다가 라인이 추가되면 이 정보를 logstash 에게 전달해준다. logastsh 는 filebeat에서 전달한 정보를 특정 port로 input 받는다. 받은 정보를 filter 과정을 통해 각 정보를 분할 및 정제한다. (ip, uri, time 등) 정리된 정보를 elasticsearch 에 ouput 으로 보낸다. (정확히 말하면 인덱싱을 한다.) elasticsearch 에 인덱싱 된 정보를 키바나를 통해 손쉽게 분석을 한다.
계속해서 이런 문제가 뜨네요 Exception in thread "main" java.nio.file.AccessDeniedException: /home/bluesky/ela/elasticsearch/config/jvm.options at sun.nio.fs.UnixException.translateToIOException(UnixException.java:84) at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102) at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107) at sun.nio.fs.UnixFileSystemProvider.newByteCha..
/etc/yum.conf 파일을 열어서 installonly_limit 값을 조정 cachedir=/var/cache/yum/$basearch/$releasever keepcache=0 debuglevel=2 logfile=/var/log/yum.log exactarch=1 obsoletes=1 gpgcheck=1 plugins=1 installonly_limit=2 #부트 커널을 몇 개까지 boot 파티션에 보관할지 지정 # 위와 같이 지정시 최근 2개의 커널만 boot 파티션에 보관
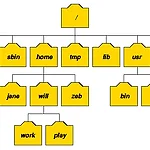 [이론] 리눅스 디렉토리 구조
[이론] 리눅스 디렉토리 구조
리눅스의 디렉토리 혹은 파일 시스템 구조는 윈도우와는 조금 다른 구조를 가지고 있습니다. 기본적으로 디렉토리를 구분하는 '/'(슬래시)는 리눅스에서 사용하고 윈도우는 반대인 '\'(역슬래시)를 사용하죠. 디렉토리 또한 그 명칭을 리눅스에서는 디렉토리(directory), 윈도우에서는 폴더(folder)라고 불리웁니다. 리눅스 디렉토리 구조 (그림 출처 http://www.doc.ic.ac.uk/~wjk/UnixIntro/Lecture2.html) 리눅스 파일 시스템 구조 리눅스 시스템의 디렉토리 구조는 전체적으로 역 트리(tree) 구조를 하고 있습니다. 그리고 명령어의 종류와 성격, 사용권한등에 따라 각각의 디렉토리들로 구분됩니다. 리눅스 배포판들은 '리눅스 파일시스템 표준' 인 FSSTND(LINUX..
1. 팬더스(pandas) 팬더스는 파이썬을 이용한 오픈 소스 데이터 분석 도구입니다. 계산 과학 분야에서 사용하는 기본 패키지인 Numpy를 기반으로 만들어서 매우 빠르고, 복잡한 데이터 처리 작업을 SQL등의 쿼리를 다루는 것보다 간편하게 할 수 있습니다. 팬더스의 특징 부동 소수점 데이터 뿐만 아니라 빠진 데이터(NaN으로 표시)를 손쉽게 처리 DataFrame 및 상위 차원 개체에서 열을 삽입하고 삭제할 수 있습니다. 개체를 레이블 세트에 명시적으로 정렬하거나 사용자가 레이블을 무시하고 Series, DataFrame 등으로 데이터를 사용할 수 있습니다. 데이터를 집계하거나 변환하기 위해 데이터 세트를 분할할 수 있는 강력하고 유연한 그룹 기능 파이썬이나 Numpy 데이터 구조의 비정형 인덱스 데..
지난 시간에 이어서 진행되는 점 참고바랍니다. 1. 작업 분배 : 큐에 넣고, 여러 개의 워커가 가져가고, 작업 종료 확인하기 퍼블리셔 => 큐 => 컨슈머 1,2 퍼블리셔가 생성한 메시지를 메시지 큐에서 컨슈머 1과2에 나워 전달합니다. 지난 시간에 한 예제와 규모를 조절하면 비슷하나 이번 예제는 컨슈머가 작업한 후 해당 작업이 정상적으로 완료되었는지 확인하는 것과 퍼블리셔, 메시지 큐 서버, 컨슈머 중 어느 하나에 문제가 생겼을 때 해당 데이터를 어떻게 보존시킬 지입니다. #메시지 센더 구현 #new_sender.py import pika # 무작위 수를 생성하는 random 모듈을 임포트합니다. import random # 서버와 연결을 맺습니다. connection = pika.BlockingCo..
 [메시지 큐 만들기]RabbitMQ를 이용한 메시지 큐
[메시지 큐 만들기]RabbitMQ를 이용한 메시지 큐
RabbitMQ를 사용해서 메시지 큐를 만들고, 큐에 메세지를 넣고, 그 메시지를 가져가는 작업을 해보겠습니다. 1.메시지 큐 메시지 큐는 서로 다른 프로그램 사이에 공유할 수 있는 무제한 크기의 버퍼입니다. 이 큐를 이용해서 데이터를 만들고, 큐에 쌓아두고, 큐에서 데이터를 빼내어 순서대로 처리하거나, 라운드 로빈 방식으로 분배해서 처리하거나, 규칙에 따라 여러 가지 작업을 할 수 있습니다. 즉, 메시지 큐는 사용자가 입력한 메시지를 보낼 때의 중간 자료구조임을 알 수 있습니다. 위키 백과 : https://ko.wikipedia.org/wiki/메시지_큐 2.RabbitMQ 소개 RabbitMQ는 사용하기 간단하고, 대부분 운영체제에서 실행되며, 메시지 큐의 표준 중 하나인 'AMQP(Adva..
이번 시간에는 스크래피를 설치하고, 프로젝트를 생성하고, 크롤링의 핵심이 되는 아이템 설정하기까지 살펴보겠습니다. 1. 스크래피 설치 set swap # swap을 첨부하는 이유는 나중에 xml을 설치했을 때 메모리 공간 확보를 위해서 입니다. sudo fallocate -l 4G /swapfile sudo chmod 600 /swapfile sudo mkswap /swapfile sudo swapon /swapfile echo "/swapfile swap swap sw 0 0" >> /etc/fstab echo "vm.swappiness = 10" >>/etc/sysctl.conf echo "vm.vfs_cache_pressure = 50" >> /etc/sysctl.conf Install Scrapy..
파이썬을 이용해 간단한 크롤링 애플리케이션을 구현해보겠습니다. 참고한 책은 python 개발자를 위한 파이썬이라는 책을 참고하여 구현하였습니다. 먼저 스크래피(scrapy)를 사용합니다. 스크래피 파이썬으로 만들어진 대표적인 크롤러입니다. 크롤링의 프레임워크라고도 할 수 있습니다. 스크래피의 장점 - 스크랩할 항목 유형을 정의하는 클래스를 만들 수 있습니다. - 수집한 데이터를 원하는 대로 편집하는 기능을 제공합니다. - 서버에 연동하기 위해 기능을 확장할 수 있습니다. - 크롤링 결과를 JSON, XML ,CSV 등의 형식으로 내보낼 수 있습니다. - 손상된 HTML 파일을 분석할 수 있습니다. 스크래피를 이용해서 크롤러를 만드는 대략적인 과정 1. 크롤링할 아이템을 선정 2. 실제 크롤링할 스파이더(..